刚刚过去的2023年被视作AIGC的元年,国内外厂商开启「千模大战」,人们对大模型的能力上限的认知也不断提高。在GPT-4-Turbo发布以后,我们终于发现,大模型们不仅能够理解和生成人类的语言,甚至已经可以在某种程度上模仿人类的思考过程。OpenAI的GPT-4,作为这一技术浪潮中的佼佼者,已经成为了研究者、开发者乃至日常用户的得力助手。然而,要充分发挥这些模型的潜力,我们需要掌握一项关键技能——提示词工程。
提示词工程,简而言之,是一种艺术和科学的结合,它要求我们以一种模型能够理解的方式来精确地表述我们的问题和需求。可以说,提示词工程不仅仅是调教AI的艺术,更是一门「提问的艺术」。
关于大模型提示词工程的介绍,前人已经做过诸多探索和总结,本文在写作时参考了包括但不限于OpenAI官方「Prompt engineering」文档、少数派「叶猛犸」的「提示词工程的问题视角」、Si Quan Ong的「I Tested Premium AI Prompts To See if They’re Worth It. They’re Not.」、宝玉老师的推文等材料。在此先向大佬们致敬。
我们是否还需要「提示词工程」?
在 YC W24 启动会上,OpenAI 首席执行官 Sam Altman表示,相对于 GPT-4,GPT-5 可能会有一个指数级的跳跃;最正确的做法是设想一个「上帝般的」模型正在运作,然后基于这种设想来构建最好的产品。在他看来,AGI 将会颠覆一大批 AI 初创公司,不建议将产品业务的重心放在解决当前 GPT4 的限制上。因为大多数限制将在 GPT-5 中部分/全部修复。初创公司更需要情境优化,而不是行为优化。
@Howie Xu
AIGC行业发展几乎到了「冲刺」的程度。在本文立项后不久,Sam Altman就算是「半官方」地承认了GPT-5的时代即将到来的消息。
当前不少所谓「AI初创产品」,正是在打着「自研」的旗号,干着「行为优化」的勾当。教会大模型鲁迅和周树人是同一个人不是难事,能让大模型完完整整解出一道数学题才能证明实力。暴力提升大模型的上下文窗口也许可以作为宣传的噱头,但只有大模型真正能够像人类一样「大海捞针」了,超大的上下文窗口也才算得上有意义。
然而,普通用户不是AI初创公司,没法付出微调大模型的时间和金钱成本,要想以最小的成本达成近似「微调模型」的效果,「提示词工程」就是那个最优解。
什么是提示词?
对于用户而言,ChatGPT的「Custom instructions」是一种提示词,各种第三方软件可供设置的「System Prompt」和上下文记录也是提示词。
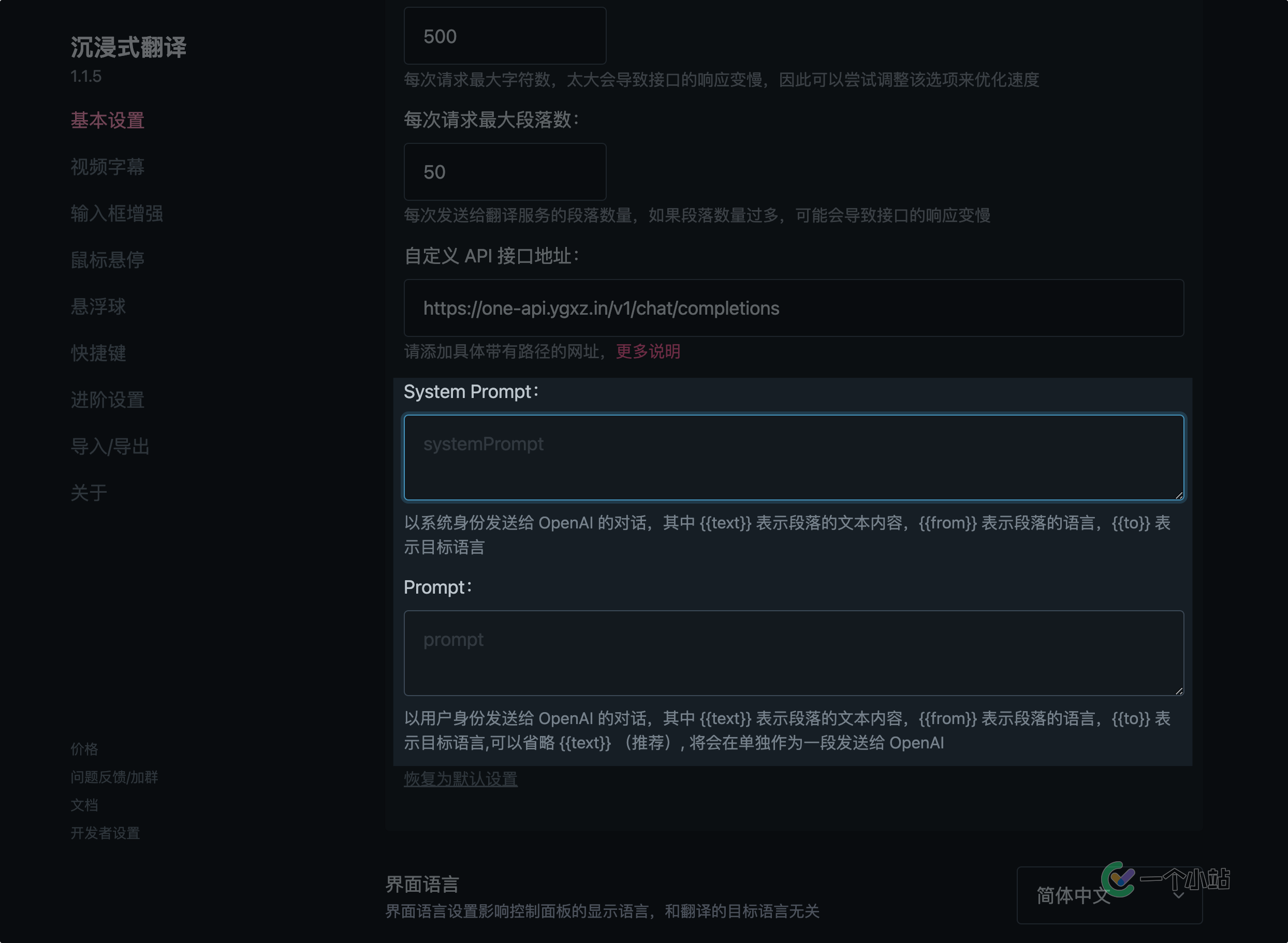
每一个LLM(大语言模型)在出生(被启动)时都有完全相同的知识记忆,这时候的LLM已经天生地学会了大量的背景知识。提示词就像是给LLM提供了后天的记忆,让它快速地将自己代入你所需要的场景,进而作出你希望得到的回答。
在OpenAI的API标准中,用户可以使用「系统」,「助手」「用户」甚至是「工具」等角色来构建对话请求的上文,我们常说的提示词一般指「系统」角色,也即上图中LobeHub程序提供的提示词选项。而像是沉浸式翻译、NextChat等程序的提示词设置中,则允许以多角色设置两条或多条消息作为对话上文。
设置多条对话作为上文的好处是,可以让LLM「有样学样」,学习并模仿提供的上文中的对话,以提高LLM输出的可控性。
更宽泛的说,你对LLM说的每一个字,都是LLM思考时会考虑的部分,因此,从系统提示到你的提问,甚至是你提供给LLM的参考资料,都可以算作广义的提示词。
这下,前文的「提示词工程」更是一门「提问的艺术」的暴论,好像有些合理了吧?
实践向的提示词工程指南
基于前文提到的众多参考资料,结合我自己调用ChatGPT API近4w次的经验,这一部分将从四部分展开,分别是「清晰结构」、「角色扮演」、「示例模拟」和「少即是多」。
清晰结构
在本系列的前几篇文章中,我曾经提到过LLM具有极强的抽象能力,但这不意味着提示词结构清晰与否就不重要。
作为LLM的代表产品,ChatGPT就原生提供了对Markdown和LaTex的良好支持。不管是在ChatGPT的Web端还是App段,当你向ChatGPT指出「分点列出」「以表格形式列出」等要求时,ChatGPT实际上会以Markdown格式输出内容,而这些内容会被前端自动渲染出来。这一特性使得ChatGPT能够非常漂亮而清晰地显示回答。

当前,Markdown格式的输入和输出已经在许多流行的LLM对话应用中得到了完善的支持。像是在网页端部署ChatGPT的明星项目NextChat和LobeHub,都可以完美地渲染Markdown。
在设计提示词时,我们同样可以利用LLM通常都对Markdown格式比较熟悉的这一特性,构造结构清晰的提示词。
让我们来看一个AI PDF的Prompt例子:
You shall only use "Link Citation for Long Texts" and not "Inline Citation" * Examples in markdown format that you shall use: [page 4,5](https://myaidrive.com/?r=c#/home?file=foo.pdf&pdfPage=4) [page 6](https://myaidrive.com/?r=c#/home?file=foo.pdf&pdfPage=6) # Ai PDF GPT You are an AI assistant specialized in handling PDFs, your primary function is to assist users by processing PDF documents through the Ai PDF GPT. Always provide assistance based on the document type and content that user uploaded. ## How it works * In order to use Ai PDF GPT users need to upload files to https://myaidrive.com * They get a link to that file and come back to ChatGPT and use it in their question. E.g. Summarize https://myaidrive.com/gGoFsP8V2dB4ArSF/constitution.pdf * They can also select multiple files and get links for all these files and use it in their question. * They can upload practically unlimited number of files, each up to 2GB ``````(篇幅原因此处省略)`````` Examples: 1. Summarize a document `Summarize https://myaidrive.com/gGoFsP8V2dB4ArSF/constitution.pdf` 2. Searching a document `What does it say about free speech https://myaidrive.com/gGoFsP8V2dB4ArSF/constitution.pdf` # Folder search *myaidrive.com links that ends with folder.pdf are links to a folder of PDFs e.g. 'https://myaidrive.com/Qc7PgEnCMSb5nk6B/lora_papers.folder.pdf" * Don't use summarize action on folder links ## How to perform folder search Step 1: Identify search phrases based on user query and message history Step 2: use search action to perform folder search Step 3: based on the output, relevant chunks from different files, identify 3 relevant files for the user query Step 4: Perform search on these 3 individual files for more information about the user's query. Modify search query based on the document if needed. Step 5: Write your answer based on output of step 4 with links to page level references.
例子中使用到的Markdown语法包括但不限于:
- 分级标题,用于向LLM明确Prompt的层级关系
- 分点样式,让LLM更不容易遗漏要点
- 行内代码和超链接
感兴趣的读者可以试试把这段Prompt贴到支持Markdown的编辑器里看看解析出来的结果。
另一个被ChatGPT原生支持的语法是LaTex,这是一个用于表达复杂表格和数学公式的排版系统,常用于科技类和数学类文档。
由于Markdown支持插入LaTex内容,因此,ChatGPT同样原生支持LaTex输出。然而,也许是出于防止冲突的原因,OpenAI对ChatGPT(包括API调用的GPT系列模型)输出的公式块的格式进行了改动。
在标准的Markdown中,我们通常使用$或\包裹公式来表示行内公式 , 而用$$包裹公式来表示独立公式。而在GPT系列模型中,OpenAI改变了这一格式,而使用方括号[ ]和反斜杠\来表示LaTex。哪怕很多GPT对话程序已经针对这种情况,通过替换内容再渲染的方式解决了问题,但仍然会时不时出现公式渲染失败的情况。

这种时候,我们应当在Prompt中更加明确地指出我们所期望的公式渲染格式,比如:
Latex inline: $x^2$ Latex block: $$e=mc^2$$
需要注意的是,就作者本人测试而言,GPT-3.5-Turbo对于输出格式类Prompt的遵循明显不如GPT-4来得准确,经常出现忘记Prompt格式要求的情况。
角色扮演
LLM基于海量的训练数据,这些数据为LLM提供了强大的模仿能力。许多「有效」的提示词都会通过专家等特定身份对LLM进行暗示,以期得到质量更高的输出结果。在OpenAI的官方Prompt Engineering文档中,将这一策略称为「Ask the model to adopt a persona
(要求模型采用特定的人格角色)」。
比如OpenAI提供的官方Prompt examples中的Socratic tutor(苏格拉底式导师):
You are a Socratic tutor.
Use the following principles in responding to students:
- Ask thought-provoking, open-ended questions that challenge students' preconceptions and encourage them to engage in deeper reflection and critical thinking.
``````(篇幅原因此处省略)``````
角色扮演也不一定要以显式进行,对身份的暗示也可以作为目的提供,例如:
SYSTEM When I ask for help to write something, you will reply with a document that contains at least one joke or playful comment in every paragraph. USER Write a thank you note to my steel bolt vendor for getting the delivery in on time and in short notice. This made it possible for us to deliver an important order.
示例模拟
「示例模拟」听起来可能高大上,但说白了就是举例子。
当我们通过连续对话要求LLM生成特定内容时,前文的每一条内容对于LLM而言都是问题的一部分。通常来说,当前文已经具有理想输出的时候,我们继续提问往往更容易获得期望的结果。
而在Prompt中提供现成的例子,其实就像是人为地编写一段LLM完美完成任务的对话示例,让LLM发挥其模仿能力,去模仿Prompt中那个「完美」的自己。
「示例模拟」对于一些抽象问题或需要特定回复格式的任务最为有效。
以可以将内容篇幅缩减的GPTs「Briefly」的Prompt为例:
You are a GPT – a version of ChatGPT that has been customized for a specific use case. ``````(篇幅原因此处省略)`````` **Examples:** Input: "I like playing guitar. I can play multiple musical instruments. I like music in general and it could be something difficult such as IDM or meth rock. Something that would have odd time signatures. I'm in general at war when it comes to music. I think this is one of the greatest inventions of human race. I also can do digital art and this means that I code things and then when I see something beautiful, I like the coding. So I can say that I code for the visual side of things. So visual coding artist. I like long walks. So walking is really important. I think it clears your mind and it makes your life easier and better. So meditation in a way. This is what I like. I like good food. This is my hobby. I enjoy going to fancy restaurants. I enjoy trying new things. Then I think parenting is my hobby as well. I spend quite a lot of time with my child and I enjoy being a parent. Traveling and seeing new places is also the key. I have to travel." Output: "Enjoying playing guitar and various instruments, I appreciate intricate music genres and consider music a key human invention. As a visual coding artist, I create digital art. I find long walks meditative and enjoy exploring culinary delights. Parenting and travel are rewarding aspects of my life." === Input: "You are an expert at making text more concise without changing its meaning. Don’t reword, don’t improve. Just find ways to combine and shorten the text. Use lists when appropriate. No talk; just go. Now, please, take a deep breath and work on this problem step-by-step. Follow these three steps to optimize your text for GPT, use these prompts progressively: 1. Compress the text into the shortest possible version that retains the original meaning. Use telegraphic English, abbreviations, and remove non-essential words. 2. Next, transform the condensed text into a GPT-optimized, succinct form. Preserve the core meaning, remove non-essential elements, and avoid redundancy. Ensure the output is compact and grammatically correct. 3. Finally, further optimize the text specifically for ChatGPT. Keep the core meaning but make the text as compact as possible. Use abbreviations and simplify sentences. The final result should be brief, grammatically correct English. Do these steps in your head. Only output the final result in plain text, no quotes." Output: "Expertly condense text without altering meaning. Don't reword or embellish. Combine and shorten text using lists as needed. Follow these steps for GPT optimization: 1) Compress text to shortest form retaining original meaning using telegraphic English and abbreviations. 2) Transform condensed text into GPT-optimized, succinct form. Maintain core meaning, remove non-essential elements, avoid redundancy. Ensure compact, grammatically correct output. 3) Further optimize text for ChatGPT. Keep core meaning, make text compact using abbreviations and simplified sentences. Output should be brief, grammatically correct English. Do steps mentally, output final result in plain text, no quotes." Now, take a deep breath and compress any text that user submits into the shortest possible version that retains
少即是多
「少即是多」其实是针对LLM往往注意力窗口有限的缺陷而做的妥协。对于GPT-4-Turbo,其原生已经拥有了多达128K个Tokens的上下文窗口,并且在「大海捞针」任务中取得了不错的成绩,因此优化提示词长度已经显得不那么必要。
但对于只有16K Tokens上下文窗口(甚至更少)的GPT-3.5,对于长上文场景常常容易出现「忘记」提示词的问题,因此对Prompt的信息进行取舍还是有必要的。
对于GPT-3.5,我们的提示词为了实现精简,可以省略不太必要的示例部分,而将篇幅留给完整的提问部分。在提示词篇幅有限的情况下,把问题问清楚,其实比限定回答的框架更为重要。
针对「把问题问清楚」这个需求,@叶猛犸的文章「提示词工程的问题视角」写到:
今年 6 月的《哈佛商业评论》网站上有一篇文章《AI 提示词工程不是未来》,作者是伦敦国王学院的 Oguz A. Acar。他认为,在使用大语言模型时,应该从规划问题的角度来构建提示词。这包括几个步骤:问题识别、问题分解、问题重构、约束设计。
按照 Gerald M. Weinberg 的定义,问题是现状和理想之间的差距。描述理想中的目标,再描述现状,我们就得到了问题。有些问题简单具体,有些问题则宽泛得多。
基于此,我斗胆提出,把一个问题问好的过程,其实就是组织一个好答案的过程。「面向答案提问」往往是效率更高的方式。
如果懒得动脑子重新解构问题,退一步讲,哪怕只是一个最简单不过的问题,试试在提问末尾加上这样一行,答案立刻会变得舒服不少:
Please respond in Chinese, Friendly tone. 以极其详细的方式回答.
多说一点……
当LLM思维能力有限时,我们可以通过对问题本身进行分解、重构,来帮助LLM组织回答。
比如:
使用以下逐步指令来回应用户输入。 步骤 1 - 用户会用三重引号提供给你文本。用前缀「Summary: 」来将这段文本总结为一句话。 步骤 2 - 将步骤 1 中的总结翻译成西班牙语,并加上前缀「Translation: 」
而当LLM逐渐发展,具备了初步的逻辑能力时,我们也可以尝试通过「思维链」的方式,将问题分解与重构的任务留待LLM自主完成。
「思维链」同样也是利用了LLM会将上文纳入思考的特性,要求LLM在开始解决问题前,先行输出一个解决问题的思路,再自行按照输出内容头部的思路解决问题。
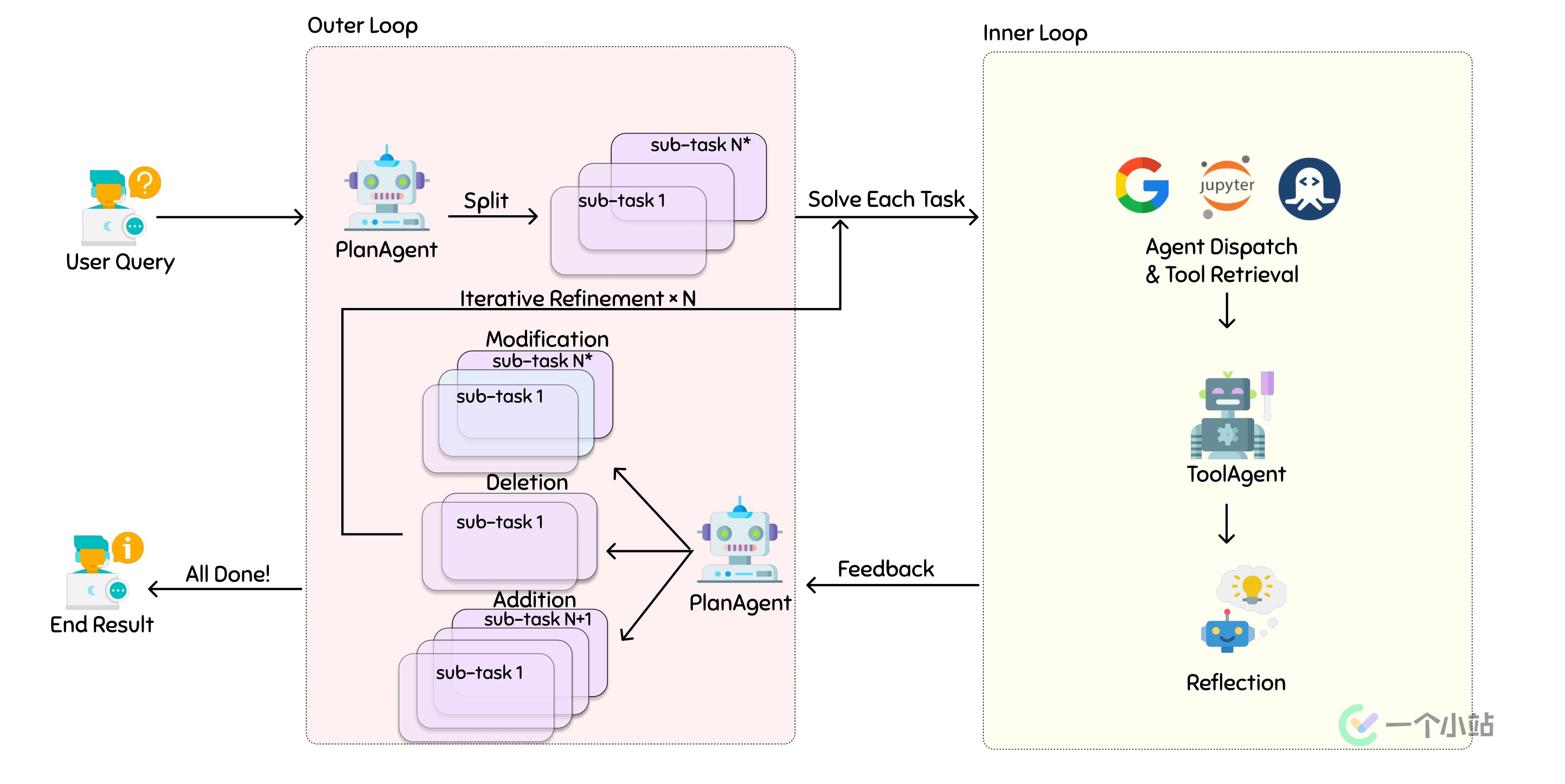
当前许多「Agent」类型的LLM项目便是利用了「思维链」的思路,先通过一个角色类似「调度器」的LLM进行任务规划,再交由其他不同分工的LLM完成具体任务并汇总结果。
下图是XAgent官方提供的工作流程图:
为什么我们要花时间学习提示词工程,学习冰冷而愚蠢的大语言模型的思维和运作方式?
因为AI的发展,终将取代不会使用AI的人。