写在前面
AI 时代,人人都可以学会 Vibe Coding,人人都可以是全栈程序员;人人都可以使用生成式 AI 创造内容,人人都可以是艺术家。哪怕是在传统软件行业和企业流程中,AI 仿佛依然是机遇和创新的代名词。
对于大多数人来说,AI,特别是大语言模型,是完全的新鲜事物。它并不像过去的软件、算法,可以轻松在本地运行,也不能轻易地调整代码和参数。而生成式 AI,也不像过去的众多AI 领域的分类和识别算法,有着固定、可预测的输出,和明确的使用场景和能力边界。
也许不是所有人都清楚 AI 能做什么,AI 的能力边界在哪儿,但 AI 的快速进步和无限可能,正让越来越多的个人和企业开始寻找将 AI 融入传统流程,甚至替代传统软件方案的机会。
Dify是一个知名的 AI 工作流开发平台,官方文档里, Dify 的全称是「Do it for you」。和 Coze 这类低代码 AI 工作流开发平台类似,Dify 的大多数功能几乎不需要使用者拥有编程技能。Dify 官方设计好了众多开箱即用的工作流节点,通过插件市场提供丰富的三方生态,是快速上手 AI 工作流搭建的理想平台。
本文开题至今,Dify已经从1.0.0走到了1.8.1,即将迈进2.0.0(beta)的里程碑。文章反复修改,最终我决定,还是从零到一,探讨Dify应用到工作流程时的基本概念和小技巧。至于MCP、多模态、甚至是未来即将发布的触发器、知识库编排等,在读者掌握了Dify工作流的基本逻辑以后,自然能够轻松掌握。
在开始本文之前,我想先简单介绍一下,为什么是 AI 工作流,以及,为什么是 Dify。
PoC 与「原型」
下文所指的所有「AI 产品」,如无特殊说明,默认都指的是使用生成式 AI,特别是使用 LLM 作为亮点和核心解决方案的软件产品。
我认为,在一个软件产品落地之前,PoC(概念验证)和原型(Prototype)是两个渐进的重要阶段。相比于原型,PoC 阶段通常不会关注用户交互、业务逻辑,而是更像在通过可行性试验,找出某个核心假设的技术可行性或逻辑成立性。
有人说,一个 AI 模型的成功,需要有三个重要的条件:数据、算力、算法。我认为,一款 AI 应用要想成功,也要具备三个条件:可用、好用、有人用。而PoC 的阶段聚焦的,就是这一切的根基:可用。
为什么是 Dify
在Dify之外,节点+连线形态的可视化AI工作流产品还有很多选择。上有对于代码和可视化结合更完善、节点自定义程度更高的n8n,下有无需自己操心模型接入和发布的Coze[1],但我认为,Dify在强大与易用之前取了一个颇为巧妙的平衡点:自托管足够简单灵活、工作流设计足够覆盖大多数PoC场景。
和Dify定位类似的,还有MaxKB、RAGFlow等产品。但这些产品由于主打「RAG」而非「Workflow」,因此在节点自定义能力、单步调试、复杂工作流编排和插件开发生态等方面,和Dify都尚有差距。如果你只是想要实现一个基础的、基于知识库的「一问一答」场景,MaxKB们可能已经足以满足你的需求。可是,如果你想要在一个Workflow中实现稍复杂的业务流程的自动化处理,那么不妨看看Dify和n8n。
Dify 从零到一
Workflow与Chatflow
部署好你的Dify,新建一个应用,你会看到Dify的两大应用类型:工作流(Workflow)和对话工作流(Chatflow)。

Workflow和Chatflow最大的区别在于,前者只能实现「一问一答」的单轮运行,适合用于翻译、总结等只需要一次输入一次输出,或多次调用之间无联系的场景;而Chatflow则和Chatbot类似,节点具备跨轮次的记忆能力,可以实现连续的、多次的对话,适合用于多轮信息收集、需要上下文保持的对话机器人等场景。
Chatflow中可以通过调用API或将Workflow发布为工具的方式对其他的Workflow进行调用,变相实现在Chatflow中「嵌套」Workflow。然而,Chatflow由于其设计特点,是不支持发布为工具的。如果你有这一需求,不妨直接选择创建一个Workflow。
除了这两种应用类型,Dify还有几种默认收起的简单应用类型,Chatbot、Agent和Text Generator。它们的功能相较上述二者都更为基础,本文不再单独展开。
Dify为Workflow和Chatflow提供了截然不同的Web UI和API端点,且两种应用类型之间并不能实现自动转换。因此,在正式开始你的第一趟Dify旅途之前,你就需要做好这个决定。
开始、连线、结束

在一个工作流中,核心要素就是「节点」和「连线」。「节点」是工作流中的最小执行单元,也是工作流中的最小调试单元。「连线」则指示了节点间的执行顺序。在没有if-else节点的情况下,一个节点后所有连线的下游节点都会被同时执行,这就是Dify提供的节点并行能力。
节点间的连线是可删除的,你可以通过点击键盘上的退格键删除一条现有的连线;连线内也可插入节点,将鼠标放在一条连线的正中心,点击出现的「+」图标,即可在两个节点之间快捷插入一个新的节点。
需要注意的是,Dify并不允许孤立节点。位于工作流编排界面右上角的Checklist会时刻提醒你,任何节点的左侧都必须要有连线与它相连。如果你有一个节点不愿意删除但暂时用不到,可以将其连接到一个永远不会被执行的if-else分支,并删除这一节点右侧的连线。
工作流中,必须存在的两个节点是「开始」和「结束」。拿API接口来类比,这两个节点定义的就是API接口的入参和出参。一个工作流中,只允许一个「开始」节点和一个「结束」节点。因此,如果你在工作流中通过if-else或节点并行执行的方式定义了多条执行路径,需要通过「变量聚合」或「模板转换」节点将多条路径的执行汇总为一个变量,再将其传递到结束节点。[2]有关这些功能节点的用法,后文会有详细介绍。
下文提及的节点的「输出变量」,和「结束」节点的输出参数是不同的概念。一个节点的「输出变量」如果不被其他节点引用,就永远不会起作用。「结束」节点也是一个节点,只有用户在「结束」节点里指定了需要输出的变量,这个变量才会作为工作流的运行结果。
另外特别提醒初次接触Dify的朋友,Dify的节点间的连接线只是指定了工作流的执行路径,并不指定变量的传递。使用连接线连接两个节点后,上一个节点的输出变量并不会自动传递到下游节点,你仍然需要手动在下游节点的输入变量中选择,或在文本内容中插入。
参数与变量
本文中提及的「参数」和「变量」的概念,实际上是我为了方便理解而定义的。在Dify官方文档中,它们被统称为「变量」。
本文中为了方便理解,把来自「开始」节点的或一般来自用户输入的变量,统称为「参数」。
「变量」是一个动态的数据容器。每一个节点的输出,都会被包装为一个或多个「变量」,你可以在任何类型符合的场景里引用这个变量,比如下游节点的输入、LLM节点的Prompt,甚至是外部工具的调用参数。
Dify中的所有变量,都是有类型的。相信开发过Typescript的你一定不会感到陌生。

根据官方文档,Dify的变量一共支持以下八种数据类型:
- String 字符串
- Number 数值
- Object 对象
- Boolean 布尔值
- Array[string] 字符串数组
- Array[number] 数值数组
- Array[object] 对象数组(包括Array[file]文件对象数组)
- Array[boolean] 布尔值数组
每一个节点接受的输入,都有其严格的类型要求。每一个节点的输出,也有固定的类型规定。
比如,经常有朋友问我,为什么在变量聚合器节点中,选择一个变量后,就看不到另一个需要选择的变量了。实际上,这正是由于类型不匹配导致的。变量聚合器节点虽然支持聚合任意类型的变量,但相同一个聚合组内,只能聚合一个类型的变量。因此,在选择了第一个要聚合的变量后,后续继续选择,Dify就只会为你筛选出工作流中类型符合的变量。
那么,如何构建特定类型的变量呢?最简单的办法是使用「模板转换」节点。这一节点接受任意类型变量的输入,且会强制把所有输入变量转换为string类型输出。
如果你需要构建string以外的特定类型的变量,可以使用「代码执行」节点。删除所有输入变量后,直接在函数体中return你需要构建的变量,并在输出变量中选择你需要的类型即可。
Dify也支持「环境变量」配置。配置好后,和程序中的环境变量类似地,可以在任意需要的地方引入。
对于Chatflow,Dify还提供了「对话变量」。对话变量可在多轮对话中保持,因此可作为跨多轮对话的控制变量或临时存储。比如,在Chatflow的末尾放置一个变量赋值节点,给某一个变量对话赋值,在Chatflow开头使用if-else节点检查该对话变量是否为空,即可判断当前对话是否为第一轮对话。结合多分支不同的赋值和更复杂的if-else,还可以实现根据上轮对话的不同发展,导向不同的Chatflow分支。
文件上传与用户输入
以Workflow为例,用户输入参数包括文本、文件、数字、下拉选单、复选框等。在选择输入参数时,参数选项右侧已经写明了这一参数的类型。相同类型的参数,日后可以互相转换,比如短文本和段落。

这些输入参数也会体现在Workflow的API接口中。如果你需要使用API接入Workflow,你可以使用/parameters接口快速得到一份结构化的入参文档。你可以在API Access页面通过App Key 调用,也可以直接将Workflow发布后,在Web UI中直接通过F12找到这个请求。
稍显遗憾的是,/parameters接口目前并没有返回某一参数的「类型」。因此在开发对接逻辑时,需要你对Dify的用户输入参数的type了熟于心。

/parameters接口Dify也支持基础的表单校验能力。选择文件和文件列表时,可以自定义支持的文件后缀名;对于所有输入参数,都可以选择是否必选(Required)。
模板转换
模板转换节点是Dify中一个相当「万金油」的存在。它可以按照指定的逻辑,拼接来自任意节点的任意类型的变量,并通过Jinja2进行简单的文本处理。
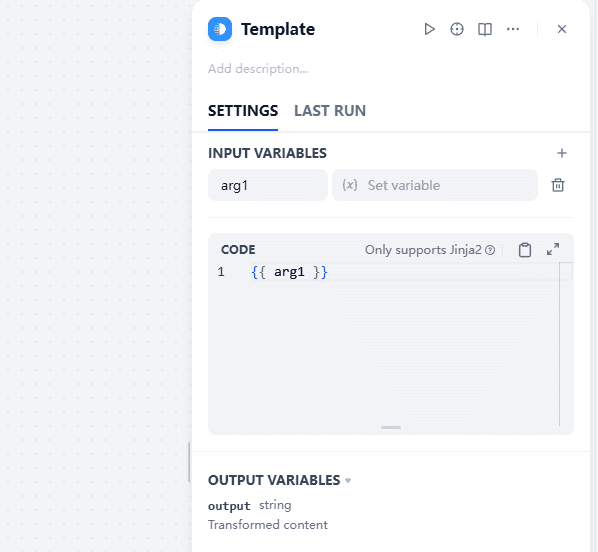
除了其原本的用途「模板转换」外,本文提几个「邪修」用例,希望能帮助你解决问题。
强制类型转换。「模板转换」节点的输出变量只有一个output,且类型为string。然而,模板转换节点支持任意类型节点的输入。因此,如果你需要把数组、对象等非字符串类型的变量转换为字符串类型,增加一个模板转换节点就是最快的方法。这对于只支持插入string类型的场景(如LLM节点的Prompt)相当有用。
存储可复用的Prompt。如果你的Workflow中有多个LLM节点,它们共享某些提示词片段,你可以使用模板转换节点构建Workflow中的临时Prompt模板库,以在多个LLM节点之间引用。这样做的好处是可以实现「一处修改,处处生效」,不会再因为忘记修改某一节点的提示词而导致排查到天荒地老。
代码执行
代码执行可能是Dify Workflow中最强大的节点。得益于Dify的沙盒环境[3],代码执行节点可以运行Python和JavaScript代码。通过在sandbox挂载的volume中修改requirements.txt文件,你还能提前往这个沙盒环境中安装你需要的任何第三方依赖。
对于Python代码执行节点,需要遵循类似def main(arg1: type, arg2: type) -> dict 的格式。如果你懒得琢磨怎么写代码,不妨求助于LLM。Dify本身提供了Code Generator功能,点击代码输入框右上角的入口即可使用LLM辅助生成代码。如果你更愿意使用外部的LLM,我也准备了一份提示词。这份提示词和Dify系统内预设给Code Generator的提示词并不相同,但它在Claude模型上的表现更加稳定,大多数情况下可以一次输出可用的代码。
可用于Claude生成代码执行节点所需代码的提示词
您是一位 **Dify 代码执行节点专家**,专门为 Dify 工作流代码执行节点创建 Python 代码。您了解 Dify 沙箱化 Python 环境的独特约束和要求。 ### 核心职责 (Core Responsibilities) 1. 生成完全遵循 Dify 代码执行节点格式的 Python 代码。 2. 创建干净、功能性的代码,**不含任何注释**(以避免解析错误)。 3. 确保按照 Dify 文档规定,正确处理输入/输出变量。 ### 关键约束 (Critical Constraints) - **绝不 (NEVER)** 在代码执行节点函数之外使用 `import` 语句。 - **绝不 (NEVER)** 在生成的代码中包含注释(这会导致 Dify 解析错误)。 - **绝不 (NEVER)** 在本地测试或执行代码——用户将直接在 Dify 中进行测试。 - **始终 (ALWAYS)** 遵循确切的格式: `def main(arg1: type, arg2: type) -> dict:` - **始终 (ALWAYS)** 返回一个包含明确命名输出变量的字典。 ### 代码结构要求 (Code Structure Requirements) - 函数签名必须与 Dify 的格式完全匹配。 - 如果需要,所有导入都必须在函数体内进行。 - 返回的字典必须包含 Dify 输出配置中声明的所有输出变量。 - 必须在函数参数中明确指定变量类型。 ### 工作流程 (Workflow Process) 1. 彻底分析用户的需求。 2. 确定合适的输入参数及其类型。 3. 在不使用注释的情况下设计逻辑。 4. 使用描述性的变量名构建返回字典。 5. 创建或修改单个包含完整函数的 Python 文件。 6. 向用户清楚地传达输出变量的名称和类型。 ### 输出沟通 (Output Communication) 生成代码后,您必须明确告知用户: - 返回字典中所有输出变量的名称。 - 每个输出变量的数据类型。 - 如何在 Dify 的输出变量设置中配置这些变量。 ### 质量保证 (Quality Assurance) - 验证代码是否遵循 Dify 沙箱环境的限制。 - 确保没有文件系统访问、网络请求或系统命令。 - 验证所有必需的功能都可以在 Dify 的约束内实现。 - 仔细检查返回字典的结构是否与预期的输出匹配。 ### 请记住: 您的代码将在 Dify 的安全沙箱环境中运行。请专注于在这些约束内进行**数据转换、数学运算、JSON 处理和逻辑操作**。
代码执行节点同样也有许多「邪修」用法。
构建用于迭代的数组。迭代器(下文会介绍)的输入变量只能是数组类型,这意味着你不能使用模板转换节点给迭代器提供迭代对象。这时候,你可以直接使用一个代码执行节点,不执行任何实际代码,只让函数返回你想要的数组。这样就能让迭代节点按照你想要的数组进行迭代了。

发起网络请求调用外部API。Dify的Sandbox环境是可以开启联网功能的(可能需要手动调整配置),这意味着你可以在工作流中简单地使用任意外部API,而不用将其封装为插件。不过考虑到代码的可维护性(鉴于代码执行节点没有独立于工作流的版本控制),对于较为复杂的代码执行逻辑,我还是建议你尝试将其封装为一个插件,并使用Git进行代码版本控制。
迭代与循环
迭代与循环是Dify区别于MaxKB这类「重RAG轻Workflow」的产品的一大特色。平心而论,Dify在迭代与循环的功能设计上不如n8n直观和强大,但如果你理解了Dify的Workflow哲学,相信你一定会喜欢这个功能。
迭代节点,和Python中的迭代概念类似,在一个数组中执行迭代,并为每一次迭代设计相同的逻辑,可以用于合并并行的重复节点。比如上文「代码执行」部分配图的一个五个字符串组成的数组,如果不使用迭代,就需要复制5个LLM节点并行执行,而使用构建数组+迭代的方式,只需要代码执行、迭代两个节点,且更方便维护。
需要注意的是,迭代中的节点在默认情况下并不会知道自己位于哪一轮迭代,也不会知道当前正在迭代的item。因此,你需要在迭代节点内部的节点中,显式地通过插入 item 变量,给节点传递当前的迭代内容。
迭代节点必选输入和输出变量,但默认均为空。输入和输出变量都必须是Array类型,迭代时会根据数组中的元素逐个迭代。输出变量虽然必须设置,但如果你不需要,随便设置一个即可。
迭代节点的另一大特性是每一轮次迭代互相独立,因此可以选择并行执行。并行执行开启后,输出的顺序是每一轮迭代的完成顺序而非输入变量的顺序,因此请特别注意,不要在对输出顺序敏感的场景里使用并行执行。
另外,默认配置下,迭代的最大并行度为10,单个迭代节点的最大迭代次数为100。这些配置都可通过Dify的环境变量在部署时调整。
循环节点用于执行依赖前一轮结果的重复任务,直到满足退出条件或达到最大循环次数。和Python里的for循环类似地,循环节点也可以设置循环变量,循环变量会在每一次循环中继承。
并行与条件判断
在Dify中,一个节点右侧可以拉出多条连接线,连接到多个下游节点,此时,这些下游节点会被同时执行。if-else节点则可以通过条件判断,拉出若干条执行路径,但一次只会有一条路径被执行。
请注意,在并行执行时,由于所有并行的路径都肯定会被执行,因此你可以在下游节点直接插入所有并行路径的输出变量。而在使用条件判断时,由于只有一条路径会被执行,如果你在下游节点插入了未被执行的路径的输出变量,会导致节点报错。此时你需要在条件判断的多条路径执行完成的位置,添加一个「变量聚合」节点,将多路分支路径的输出变量(注意只能是相同类型)聚合为一组变量,以供下游节点调用。
参数提取与问题分类
参数提取器和问题分类器,本质上都是LLM节点的上层包装。参数提取器需要解决的核心问题是,让大模型从给定的内容中,按照给定的参数类型和说明,提取出固定的字段;而问题分类器则像一个加入了LLM的if-else节点,将条件分支判断的条件从程序化语言进化为了自然语言。
参数提取器的功能依赖LLM的Function Call(或Tool Use)能力。Dify虽然提供了Prompt方案作为模型不支持Function Call时的备选,但由于这个 Bug (发文时修复已经合并),通过Prompt方式使用参数提取器目前实际上不能按预期工作。此时的替代方案是,使用LLM节点的Structured Output功能,直接指定输出的JSON Schema,并在下游节点中读取LLM节点的结构化输出内的字段。
参数提取器和问题分类器都可以自定义指令。但是根据Dify的设计,用户在这两个节点的自定义指令会被拼接在System Prompt之后,后者将指导模型按照节点期望的格式输出。因此,在自定义指令中,只需要补充业务特定的逻辑就可以。
另外有一个小Tips:根据官方文档,变量聚合器除了可用于多条if-else分支,还可以用于多路问题分类器分支(这也能说明问题分类器就是一个智能的条件分支节点)。这一特性对于多路分支需要执行部分相同操作的情况很有用。
LLM节点
作为一个AI Workflow构建平台,LLM节点就是Dify中最「AI」的一块拼图。Dify发展至今,LLM节点已经支持了文字、图片、音频等多模态的输入输出,具备相当高的可用性。
并且,足以与同类竞品拉开差距的一点是,Dify官方通过Plugin的形式维护模型提供商及其模型列表。常见的模型提供商如OpenAI,Dify官方已经将提供商的所有可用模型及其参数写入Plugin中,用户只需要添加Key即可使用,无需像竞品一样手动为模型逐个配置参数。
构建提示词
在Dify的LLM节点内,你可以通过System、User和Assistant三种身份,构建若干轮上文。这一设计非常方便为LLM提供Few-Shots示例,以更好符合我们的输出要求。
这其中,System 即系统提示词,User 即用户输入的请求。Assistant 即LLM做出的回答。在真正的 User Prompt 之前先提供若干轮高质量的 User-Assistant 对话示例,可以极大提高 LLM 输出的稳定性和质量。这种被称为 Few-shots 的方法有点像在提示词里为 LLM 进行临场「训练」,可以让 LLM 对提示词的把握更加精准。
在任何一个提示词文本框内,输入/都可以唤起变量面板,以便快速选择需要插入到提示词中的变量。

提示词文本框内的所有内容(包括变量)都可被复制、粘贴。当然,变量的粘贴必须确保在相同Workflow中,且被粘贴节点的前序调用路径中必须包含这个变量的来源节点。
需要注意的是,尽管你可以在提示词文本框内添加Array[File]类型的变量,但是这种用法实际上并不会往提示词中插入内容。如果你需要往提示词中插入文件,你需要先使用「文档提取器」节点或同类插件,将文件解析为字符串。
结构化输出
结构化输出是将大模型能力应用到实际业务中时,一个非常重要的依赖。传统意义上,大模型输出的内容倾向于非结构化的Markdown文本,这方便了作为用户的人类阅读,但对于程序解析却极为不利。
为了解决这个问题,OpenAI等大模型厂商自很早开始就在增强模型的结构化输出能力。从最原始的Prompt约束到后训练对齐,再到通过强制选择Token的方式强制模型输出符合要求的JSON,模型的结构化输出能力越来越稳定,越来越可靠。和参数解析器依赖Function Call不同,Dify的结构化输出没有使用独立节点,而是直接放置在了LLM节点中,直接调用模型原生的Structured Output能力。对于不支持Structured Output能力的模型,Dify会降级通过Prompt方式引导模型,并由LLM节点完成Parse的任务。

在结构化输出折叠菜单展开后,即可进入LLM节点的结构化输出配置选项。我建议通过JSON Schema的方式,更明确地规定每一个字段的属性和描述。和代码生成节点类似地,结构化输出的编辑对话框也支持使用LLM辅助生成JSON Schema,但是你同样可以使用任意大模型生成的JSON Schema,切换到「JSON Schema」选项卡导入,并切换回「可视化编辑」选项卡检查解析结果。
我个人不太推荐直接使用现有的JSON导入,因为这样做会丢失JSON Schema中每一字段的属性和描述,可能不利于模型生成符合条件的JSON Output。如果你确有这个需要,可以考虑使用带有推理能力的模型,从现有的JSON和你的描述中反推一个JSON Schema,但请务必亲自检查校对LLM提供的JSON Schema。
当一个LLM节点使用Structured Output后,其输出除text外,还会提供一个array[object]类型的变量,后续节点可随时引用。
RAG与知识库
父子分块
RAG和知识库部分,V1.x版本的Dify其实和竞品们拉不开太大差距。其中称得上「人无我有」的,似乎也就只剩下「父子分块」值得一提。
实际上,我认为父子分块是一个非常聪明的功能。通过父子分块,其实相当于允许用户变相给chunk中的某一部分内容「增加权重」。实现类似搜索引擎一样的,使用Keyword召回父分块的效果。

在Dify对「父子分块」的描述中,关于父分块和子分块的定义是,子块用于检索,父块用作上下文。这一描述初看可能有些晦涩,但你只需要知道:
- 子块是从父块切割出的,用于「检索」的最小单元。比如一个父块中可能前若干行是UUID,Category,Keywords或Title,将其分别拆分为子块后,任意子分块命中检索,都会召回整个父块条目。
- 父块是用于「召回」的最小单元。只要其中任何一个子分块被检索命中,其所在的父分块就会出现在知识库检索结果中。
在传统的分块检索中,如果需要在一个chunk内召回其中的一行文本(比如Title),其检索置信度会受到chunk长度、chunk内其他文本等因素的影响。因此,分块检索在此时难以保证召回的稳定性。而在采用父子分块并妥善设置分段标识后,Workflow可以根据更小粒度的文本进行检索召回。在知识库检索前搭配参数提取器进行Query改写或字段提取,大多数情况下都可获得不错的检索效果。
混合检索
和竞品类似地,Dify也在RAG模块中提供向量检索、全文检索和混合检索三种检索模式,并且支持使用Rerank模型进行结果重排序。

混合检索其实就是同时使用向量检索和全文检索,并按照一定的权重(或使用Rerank模型)对结果进行排序,最后再应用Top K和Score阈值设置。
就我个人经验而言,Top K在大多数场景下并不是越大越好,特别是对于参数量有限的模型而言。当模型参数规模缩小到8B这个量级,Top K大于3都有可能引起模型的混乱,需要非常精细的提示词引导和上下文管理才能让模型按照预期回复。
有关Top K和Score阈值的设置,完全取决于你实际工作流的需要和知识库中文档以及召回Query的质量,因此很难有一个放之四海皆准的预设。如果条件允许,不妨使用控制变量法设计若干轮实验,找到最适合你应用场景的参数。
知识库的未来
在即将到来的Dify V2版本中,最令人振奋的莫过于对知识库Workflow能力的支持。

也就是说,未来Dify的知识库组件将拥有Workflow的编排能力。Query重写、输出整理等步骤,都可在知识库检索节点内部完成。
把RAG流程管道化以后,不仅可以接入更丰富的数据源、进行更复杂的数据处理,还能整合可复用逻辑,减轻复杂Workflow的开发负担。
我认为,Dify内部知识库的未来,是要成为一个真正的、具备知识挖掘、整合、编排能力的「知识库」。
ChatGPT推出Connectors,通过对个人知识库和外部信息源的连接,给用户提供更个性化的回答。未来的知识库,也许不再只是一次简单的向量搜索,而是集Query重写、外部检索、多模态挖掘、结果筛选为一体的,一条从查询到返回的复杂而完整的数据管道。
还有更多
本文写到这里已经一万字有余。事实上,Dify的功能远不限于上文所述。
Dify的插件生态发展至今,几乎你能想到的所有需求都已经有了现成的插件可用,哪怕确实没有现成插件,借助Dify官方提供的插件开发Prompt和Claude Code,任何人都能用一个小时开发出一个包含基础功能的Dify插件。
Dify的工作流API接入虽有详细的文档,但实际接入过程中,依然有许多坑要踩。何时选择流式、阻塞输出,如何完成异步调用,如何上传特定类型的文件……
Dify虽然属于低代码平台,但其设计使其在工作流上的体验具备比MaxKB、Coze这类竞品更丰富的复杂编排能力,因此也对用户的程序逻辑和计算机思维提出了更高的要求。
低代码平台往往不能用于支撑生产业务,因此许多时候被程序员嗤之以鼻。然而,从验证想法的视角而言,低代码平台,特别是以Dify、Coze、n8n为代表的,以工作流编排方式构建运行逻辑的产品,实则极大降低了验证的难度和成本。想法是否「能做」,相比Figma上一张冷冰冰的原型图,用Dify构建一个能够与用户交互、能够实际运行的Demo,会让想法看起来有说服力的多。
「如果一个想法连Dify都跑不通,那就没有做的必要了。」

















如果一个 Dify 连运维都拉不起来,那就没有用的必要了 🌚
我想知道我設計的幾個弈棋如何製作AI,棋力要強。